Experience
What I've built and where.
Ciel
Flagship
Architect & Sole Engineer · Independent project · 2026
A hyperagent that evolves its own multi-agent interview committee. I designed and
built the entire system: the reasoning core, the ML evolution loop, real-time browser
voice, the backend, and the web app.
Ciel
FlagshipArchitect & Sole Engineer · Independent project · 2026
Ciel runs realistic, multi-round mock interviews with a committee of AI interviewer agents. You search a live role or paste a job description, and it builds the interview from the company's real hiring process, scores you as you go by voice, text, or code, then turns your weak spots into a study plan. Above the committee sits a hyperagent, a meta-agent that improves the interviewers' own questioning and scoring strategy across generations, and even rewrites how it improves.
A peek inside
Senior Engineer · asks
"Walk me through how you'd keep one noisy tenant from starving the rest."
then you answer out loud
every round scored on structure, depth, and communication, with targeted feedback.
Generation 3 · fitness climbing
the committee re-tunes its own interviewing and scoring across generations.
7-day streak · 3 cards due today
weak spots become a daily, spaced-repetition review.
The committee
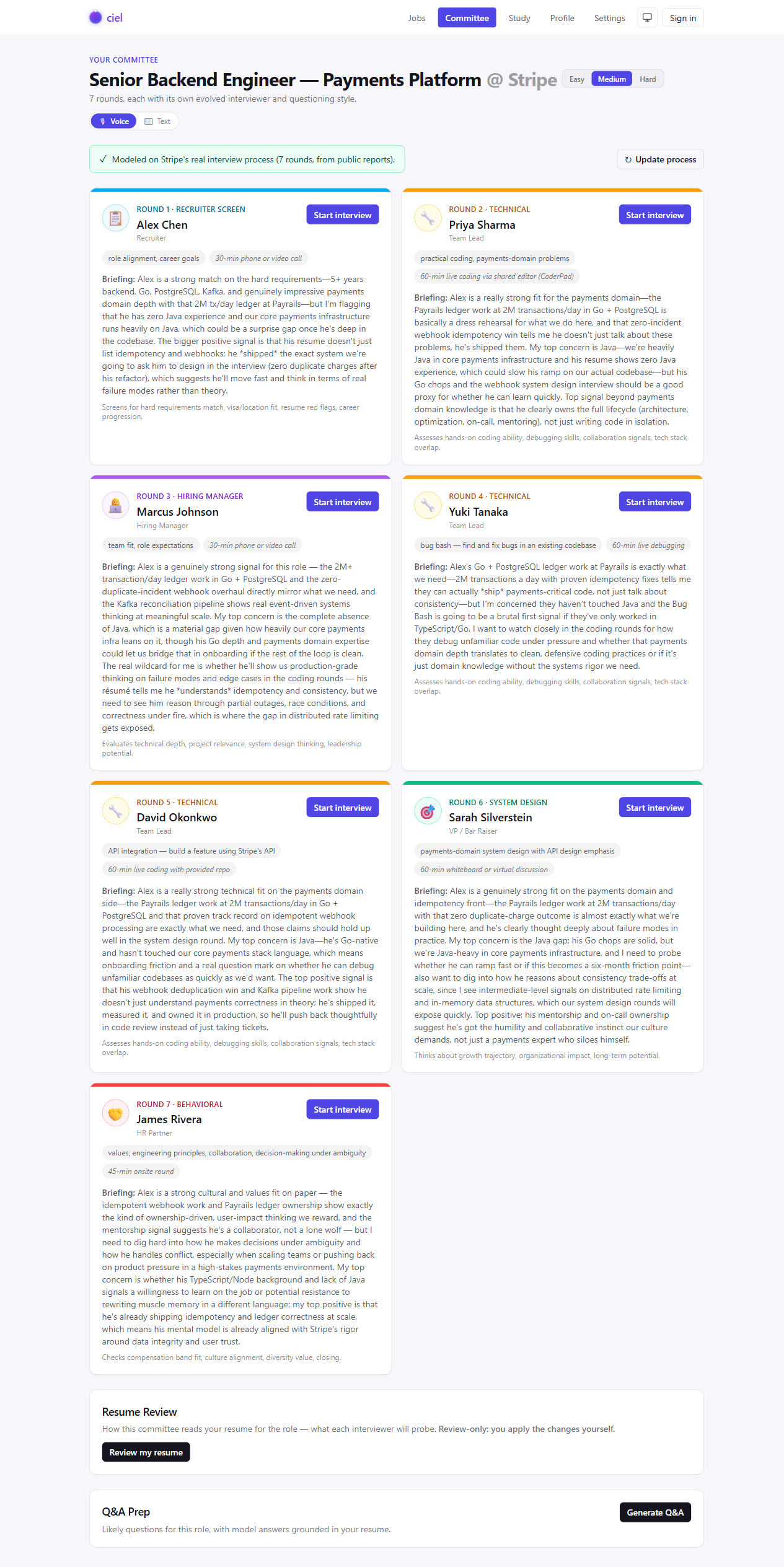
Demo walkthrough. A 2-minute recorded tour of a full evolving interview, by voice.
[EDIT] Drop your recorded demo video here (MP4 in /assets, or an unlisted-video embed).
Multi-agent committee
A committee of LLM interviewer agents, each with its own persona, focus, and questioning style, coordinated into one realistic, stateful interview.
Hyperagent self-evolution
A meta-agent rewrites the committee's questioning and scoring strategy across generations, and can revise how it improves. Improving the improver.
Dynamic interview process
The rounds are built from the company's real hiring pipeline, and can fold in your own first-hand notes. Not a fixed template.
Autonomous company research
An agent plans its own searches, reads the results, decides what it still needs, and repeats, then writes a focused company prep dossier.
Real-time voice
Interview out loud in real time, with neural voice-activity detection, natural barge-in, and human-like turn-taking, so you practice by talking.
Live coding round
Technical rounds open a real in-browser code editor (Python, JS, TS, Java, C++) whose solution the interviewer reads and reacts to.
By the numbers
How it's built
Agent orchestration. A panel of LLM agents composed from a company's real, multi-round process, each with its own role, focus, and questioning behavior, coordinated into one coherent, stateful interview.
Real-time browser voice. A self-hosted speech cascade with neural voice-activity detection and barge-in, engineered for natural turn-taking and graceful behavior in noisy, no-headphone setups.
Self-improving evaluation. A closed loop tunes the interviewing and scoring strategy against held-out labels, validated on a non-circular benchmark that measures how well it separates strong answers from weak ones.
Full-stack ownership. A typed monorepo across reasoning core, web app, and backend, with a large automated test suite and CI-style gates (typecheck, test, build) on every change.
The hard part. The moat is the self-improvement loop: a hyperagent that mutates and re-scores its own interviewers, with a train/validation split and a held-out discrimination benchmark it is never allowed to see, so gains are real and not self-flattering.
Typed monorepo, a large automated test suite, and CI-style typecheck, test, and build gates on every change. Closed-source; a guided code walkthrough is available on request.
claude-crusts
Open source
Creator & Maintainer · npm package · 2026
A published open-source CLI that analyzes Claude Code context windows to find wasted
tokens and generate fixes. 83★ on GitHub, 1,000+ npm installs.
claude-crusts
Open sourceCreator & Maintainer · npm package · 2026
A command-line tool I designed, built, and maintain. It inspects a Claude Code context window, identifies where tokens are being wasted, and generates actionable fix commands. It runs fully offline with zero API calls, which keeps it fast and private. Published to npm and adopted by developers in the wild.
Senior Software Engineer
HCLTech America · Sacramento, CA · Jun 2024 – Present
Production AI for NVMe semiconductor test data: an LLM analysis system, ML forecasting and anomaly detection, and the full-stack tooling around them.
Senior Software Engineer
HCLTech America · Sacramento, CA · Jun 2024 – Present
LLM-powered analysis system for NVMe semiconductor test data
- Architected an LLM analysis system using fine-tuning (LoRA/QLoRA) over millions of log entries to automate narrative generation, reaching 85%+ narrative quality and cutting manual analysis from hours to ~6 minutes.
- Built a 3-layer hybrid retrieval architecture combining SQL queries, BM25 sparse retrieval, and dense semantic search with Reciprocal Rank Fusion (RRF).
- Engineered an LLM guardrails and observability layer with hallucination detection and automated quality scoring, holding numerical accuracy above 95%.
ML-driven dashboard for error forecasting and anomaly detection
- Built error forecasting, anomaly detection, and root-cause insights for testers.
- Created an ARIMA-based model with Python UDFs in Snowpark ML for time-series forecasting at 84% accuracy.
- Enhanced anomaly detection with autoencoder-based UDFs to flag outliers across 2.5M+ daily test entries, with integrated root-cause diagnostics.
Internal tester dashboard, full-stack (Flask + D3.js)
- Resolved a browser crash from a 200MB+ bulk load, cutting page load from 20+ minutes to under 10 seconds by redesigning the Snowflake query architecture.
- Built a FastAPI + Streamlit clustering tool with deep-linking, auto-zoom, CI/CD, and drill-down modals, backed by a 27-test suite, used by teams to pre-screen issues before debugging.
Software Engineer
Danlaw Inc · Novi, MI · Mar 2023 – Apr 2024
Computer-vision and ML for driver safety: drowsiness detection and radar-based vehicle trajectory prediction.
Software Engineer
Danlaw Inc · Novi, MI · Mar 2023 – Apr 2024
Driver drowsiness detection
- Built an enhanced drowsiness detection system with a hybrid metric fusing Eye Aspect Ratio (EAR), PERCLOS, and Gaze score; used GANs for face synthesis and GPT-3 to refine feature extraction, for an 18% accuracy gain.
Multi-step vehicle trajectory prediction (radar)
- Designed an algorithm fusing an Unscented Kalman Filter (UKF) with a Spatio-Temporal Graph Convolutional Network (ST-GCN) to predict on-road vehicle trajectories from radar sensor data.
Research Assistant
University at Buffalo · Buffalo, NY · Sep 2022 – Jan 2023
Research engineering on web-scraping and text-analysis tooling for large-scale data acquisition.
Research Assistant
University at Buffalo · Buffalo, NY · Sep 2022 – Jan 2023
Web-scraping and data-extraction tools
- Built a Google Patent parsing tool with the BeautifulSoup Python package to extract structured data from HTML.
- Used Selenium WebDriver to scrape sites with dynamic, JavaScript-rendered content.
- Implemented text-inconsistency detection software.
Machine Learning Engineer
CIET · Feminist Pen Foundation · Remote · Jan 2021 – Jun 2022
Built TraceX, an NLP SaaS for COVID-19 infection control, plus NLP models for risk estimation and cyberbullying detection.
Machine Learning Engineer
CIET · Feminist Pen Foundation · Remote · Jan 2021 – Jun 2022
TraceX — NLP conversational interface for COVID-19 risk
- Led the design and build of TraceX, an NLP conversational interface integrated with Telegram (400M+ user base) for real-time COVID-19 risk assessments through interactive dialogue.
- Implemented conversational flows in GCP Dialogflow with intent structuring and entity extraction for personalized risk evaluations.
- Fine-tuned an ML information-retrieval model over news articles (precision 0.78, AUC 0.80) to predict infection risk.
Cyberbullying detection (deep learning)
- Designed and trained a hybrid RNN-LSTM network, using BERT for data augmentation and GPT-2 for synthetic data generation, improving accuracy by 2.4%.
Director of Administration
Feminist Pen Foundation · Remote · Aug 2020 – Jun 2022
Led administration, budgets, and HR for a 17-person cross-functional team in an Agile environment.
Director of Administration
Feminist Pen Foundation · Remote · Aug 2020 – Jun 2022
Led administration, budgets, and HR operations across a 17-person cross-functional team in an Agile environment, overseeing departmental resource allocation.